Table of Contents
This post follows from personal frustrations encountered when trying to package software for Nix. It is not aimed at discrediting the enormous amount of effort and contributions the ecosystem has put into Nixpkgs. This piece will also not be discussing details of the Nix evaluator itself. This is a purely conceptual (but practical) discussion within the Nix language about packaging, modularity and readability.
A deep dive in Nixpkgs #
A few months ago, I started reading the low-level documentation and implementation of the nixpkgs repository. One of the main challenges of nixpkgs is to find the source files of some of the expressions I encountered. A good grepping tool proved vital. I will list some of the interesting observations I made while exploring the source and some of the issues and PRs.
Cross-compilation bootstrapping #
Reading about stdenv bootstrapping,
splicing and cross-compilation was very confusing. It is not clear at first
glance what the exact data flow is that leads to stdenv.mkDerivation as we so
dearly know it. Bootstrapping for different build and run platforms is
implemented in a sliding window
fashion. The idea works well in theory but the current implementation seems to
be missing (some) clarity. The manual
also states:
Conversely if one wishes to cross compile “faster”, with a “Canadian Cross” bootstrapping stage where build != host != target, more bootstrapping stages are needed
The theory allows for an "easy" way to provide cross-compiled builds for many different combinations of build and run platforms but the currently implemented method effectively restricts the types of combinations that are possible.
Package scopes and overlays #
Nixpkgs employs a number of methods to group packages in sub sets (or scopes). Uniformity is a highly desired quality in this context. It is especially important for contributors to have great clarity in the way they can make use of a scope.
Another important quality of these scopes is the ability to allow overrides or extensions. There are multiple ways to do this. Let's have a look at some methods that are based on the calculation of a fixpoint.
"Overlay" extensions #
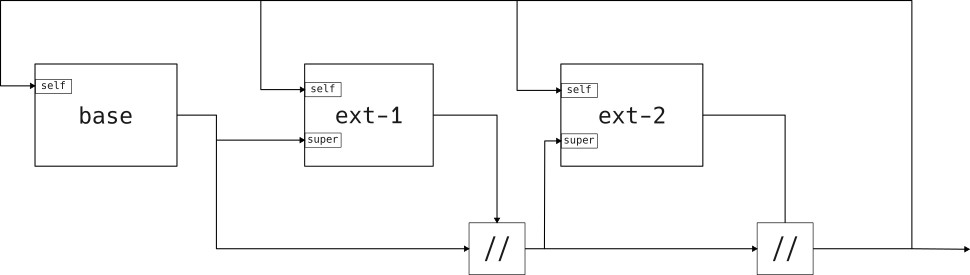
Overlays allow an extension to change everything. That means it can
- add attributes to a set
- replace attributes in a set with any value
- modify the base attribute set that all extensions are applied to
- cause changes in an earlier extension (i.e. transparency)
This turns out to be a very useful and elegant way of composing different attributes within a fixpoint. Because of the ability to let the extension override anything that was applied earlier, it is a "transparent" extension. A base set and a base set with one or more extensions behave exactly same when you look at the output and composability.
"Add-update" extensions #
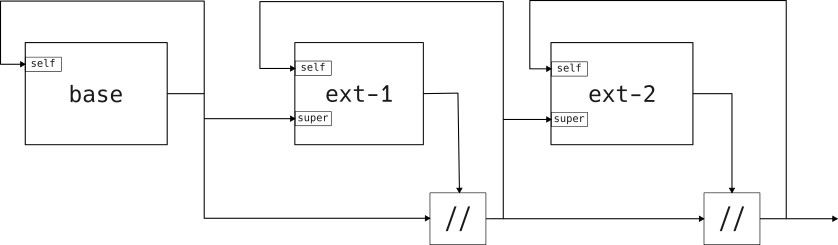
Add-update extensions allow an extension to
- add attributes to a set
- replace attributes in a set with any value
Note that this type of extension does not allow changes to an earlier extension or even the base attribute set. This makes it an interesting way to guarantee that previous stages are not affected by future extensions. I am not aware of projects that make use of this extension type.
This type of extension is not "transparent" in the way that the data dependencies can differ between their definition in an extension and their effective meaning in the final output. It is impossible to replace an attribute in the set and have this cause changes in earlier extensions that depend on this attribute and that come after the stage where this attribute was first added to the set.
"Append-only" extensions #
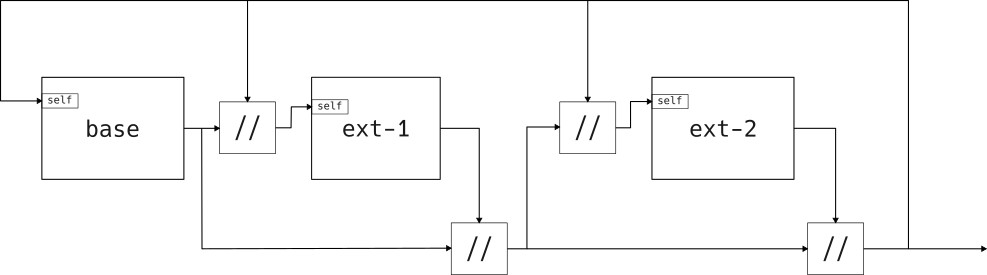
Append-only extensions allow an extension to
- add attributes to a set
- completely replace an attribute in a set (i.e. no update)
Note that this type of extension makes it impossible to modify an attribute based on its old value. There are no data dependencies allowed in the fixpoint between attributes with the same name.
Conclusion #
The overlay type is the current widely-accepted solution for applying extensions to a fixpoint calculation. It is very elegant and simple to define but it may cause more changes than initially expected due to its transparent nature.
The "add-update" extension type is more restrictive than an overlay and may be
useful in scenarios like bootstrapping stdenv. It guarantees that each
successive stage cannot interfere with previous stages, making it more
straightforward to reason about the progression. Another interesting property of
this extension type is that stages cannot depend on future extensions, making it
easier to reason about the data dependencies when bootstrapping something like
stdenv. Both overlay and append-only extensions allow this future-dependency.
The "append-only" extension type is mainly listed for illustrative purposes rather than for its usefulness. I have not (yet) been able to come up with a use case that isn't already best fulfilled by the overlay or add-update extension type.
Package/derivation definitions #
The current methods to define a package/derivation using one or more language
technologies are heavily based on the builder used in mkDerivation (i.e.
stdenv). This is certainly an interesting and useful builder but it also forces
packages to follow the stages that are defined in this builder. From the source
code it is clear that cross-compilation was not initially added to this builder
and only "patched" on at a later time.
The concept of setup hooks is also a very sneaky and hidden thing that is very necessary to have successful builds but are otherwise hard to reason about and break any composition that was done in nix by escaping through bash.
Like scopes, it is also important to have clear and uniform override semantics across different technologies, a fixpoint with overlays seems quite reasonable to use for a package/derivation definition.
A call for innovation #
The monolithic nature of Nixpkgs makes it hard to maintain for scale and adding new packages to the repository will inevitably be slow to propagate to the different channels. A more decentralized approach is necessary to allow for easier composition and faster innovation. Concepts like semantic versioning are widely accepted as a good way to move forward in a software project. This could be an interesting direction to research.
I have been experimenting with a different approach to decentralized package composition that is more advanced and useful than just adding an overlay to the global namespace of a complex fixpoint. Consider it a bit as a rewrite of the fundamentals learning from Nixpkgs and encouraging developers to innovate more freely in a modular framework.
I'm very happy to introduce corelib (by lack of a better name) as a practical experiment on providing a non-monolithic solution for sharing nix recipes and software builds. There's a number of interesting differences from Nixpkgs, some challenges to get it adopted pratically and some open questions that require discussion from the community.
Scopes as the default #
corelib starts from the idea of putting everything in a dedicated scope. This
is especially good for the modularity and increases predictability of the final
build recipe for packages. Multiple scopes are combined and evaluated into
derivations or similar. A scope always knows its own dependencies and can access
the expressions declared in these dependencies. Consider the following:
1example = mkPackageSet {
2 packages = self: {
3 one = import ./one.nix;
4 two = import ./two.nix;
5 };
6 lib = lib: {
7 add1 = n: n + 1;
8 };
9 dependencies = {};
10};
This is a package set or scope that contains two packages (named one and two)
and declares a pure function add1. Note that both the packages and the pure
functions are declared in terms of a fixpoint, this maximizes the flexibility of
a package set definition. This simple example does not have any dependencies,
hence it cannot access any other package or lib function that is not defined in
this set itself.
Because pure functions are quite a bit simpler to reason about, I'll first give an example where a dependency is used for access to additional pure functions.
1stdLib = mkPackageSet {
2 lib = lib: {
3 helper = a: b: a + b;
4 add = a: b: lib.self.helper a b;
5 }
6};
7
8example = mkPackageSet {
9 lib = lib: {
10 plus5 = n: lib.std.add 5 n;
11 };
12 dependencies = {
13 std = stdLib;
14 };
15};
There are a number of things to discuss about this example. There is a standard
library package set that only exports pure functions. This standard library can
make use of its own functions by referring to the self scope in lib. The
example package set then uses one of the functions from this stdLib dependency
by referring to it by the name that was assigned in the dependency list (i.e.
std).
This is a good example of the modularity introduced by corelib. A package set
assigns a name to each dependency, making it accessible under that name. Because
an attribute set needs to have unique values, it automatically causes
dependencies to be named by unique values. The contract between package sets
consists in the specific attributes they present in their scopes. As long as a
scope knows what attributes will be in a dependency, it can give that dependency
a fixed name and safely refer to these attributes under that dependency's
scope.
The idea of providing packages and pure functions under scope attributes is
repeated for packages. Each scope contains a fixpoint through the self scope
and all dependencies are accessible under their assigned name.
Cross-compilation #
Packages are considerably more tricky to compose than pure functions. This is
because of cross-compilation. The term "packages" is not actually a good term
here, it's open for improvement but it really means "any nix expression that
depends on a build and host/run (and target) platform". This includes packages
but also functions like mkDerivation that may already depend on the build
platform triple.
Consider the following theoretical idea for the definition of a package:
1# Minimal set of utilities.
2core:
3mkPackage {
4 /* The package recipe function -> returns derivation
5
6 This can be anything that builds from given dependencies,
7 mkDerivation is used purely for the sake of example and familiarity for
8 current nixpkgs users.
9 */
10 function = { mkDerivation, libressl, ... }: mkDerivation {
11 buildInputs = [ libressl.onHost ];
12 # ...
13 };
14 # This package has a dependency, defaults have to be specified.
15 dep-defaults = { pkgs, lib, ... }@args: {
16 inherit (pkgs.ssl) libressl;
17 inherit (pkgs.stdenv) mkDerivation;
18 };
19}
There is even more to unpack here. First of all, mkPackage allows for some
QoL functionality regarding override semantics. This is currently something I
have not worked on yet (and would currently just pass on the attribute set given
to it). This is very much an open question. The current design
makes a distinction between the recipe that builds a derivation from
dependencies and the actual dependencies that should be used. This makes the
packaging a lot more robust for ecosystem changes. There is a global contract
for what a package should behave like and it's explicit and clear in the way it
should be defined. Even if the evaluation of the package changes, its recipe can
always be reused given the proper dependencies/dependency format. This makes
only sense of course if these expressions are publicly accessible.
The scoping happens in dep-defaults. When the package/derivation is evaluated,
its dependencies are first collected through dep-defaults. These dependencies
are given directly to the function and its result is returned. Hence
dep-defaults is also able to pass on default feature flags to function. Note
that the same scoping interface is presented as is the case for pure functions.
A self scope that introduces a fixpoint for the package set and an explicitly
named scope for every dependency of the package set this package is included in.
The cross-compilation is injected through the use of "explicit" splicing. Every
package presented in the dependency scopes is automatically spliced through
attributes onBuild, onHost and onTarget. This forces the recipe to make an
explicit choice which cross-compiled dependency it should use during its build.
If the package concerns a target platform (i.e. it emits code), it will define
targetPlatform as a non-null attribute in function's return value and instead
the 6 attributes onBuildForBuild, onBuildForHost, onBuildForTarget,
onHostForHost, onHostForTarget and onTargetForTarget will be provided
instead. This shows the explicit contract that if the target platform does not
matter, each recipe must produce the exact same result for a given
buildPlatform and hostPlatform regardless of the targetPlatform that is
passed on to the dep-defaults and the function. This makes sense and is an
improvement over the current implementation in Nixpkgs.
Bootstrapping a package set for a given platform triple can be very elegantly obtained by:
1# Bootstrap for a single platform (x86_64-linux)
2pkgs = bootstrap (self: {
3 final = {
4 triple = {
5 buildPlatform = "x86_64-linux";
6 hostPlatform = "x86_64-linux";
7 targetPlatform = "x86_64-linux";
8 };
9 adjacent = {
10 pkgsBuildBuild = self.final;
11 pkgsBuildHost = self.final;
12 pkgsBuildTarget = self.final;
13 pkgsHostHost = self.final;
14 pkgsHostTarget = self.final;
15 pkgsTargetTarget = self.final;
16 };
17 };
18}) packageSets;
Given a attribute set of package scopes (packageSets), the different stages
are defined in function of the required platform triples. The different
host-target platform combinations are simply expressed in terms of an "fake"
fixpoint self. For a cross-compiled build that compiles on platform A so that
the compiled code runs on platform B, there would be 3 attribute sets defined in
the "fixpoint". The adjacent package sets must be defined correctly in terms
of these 3 attribute names taken from self. The rest happens automatically.
This approach is both incredibly more readable, elegant and expressive in terms of bootstrapping a cross-compiled package set. It does not restrict from evaluating packages for a "canadian cross" build.
CallPackage replacement #
While the dep-defaults makes it difficult to imitate the convenience of
callPackage. My current implementation makes it easier to evaluate the same
package format in the context of the package scope without exporting a package
format to the public expressions. An example is given next.
1# Minimal set of utilities.
2core:
3mkPackage {
4 function = { mkDerivation, autoCall, ... }: let
5 # The same package format can be evaluate in the same context given to `dep-defaults`.
6 helper-package = autoCall ./helper-package.nix;
7 in mkDerivation {
8 # ...
9 };
10 # This package has a dependency, defaults have to be specified.
11 dep-defaults = { pkgs, lib, autoCall ... }@args: {
12 inherit (pkgs.stdenv) mkDerivation;
13 inherit autoCall;
14 };
15}
The idea is that autoCall evaluates the same package format for the given
context of the package set that is currently being evaluated whtin. This context
consists of the self and dependencies scopes presented to dep-defaults.
While the private property of this "hidden" package makes it impossible to
provide explicitly spliced versions, it may still be useful as it corresponds to
a forced dependency equivalent to onHostForTarget.
Open questions #
With the introduced framework, it may be easier to make nixpkgs modular and decentralized. I specifically did not specify how these package scope expressions should be collected into one nix evaluation because there are numerous ways (some upcoming even) to do this. Flakes, pinned inputs and the Ekala project are amongst the possibilities.
Further questions regarding the project remain:
- How should overriding actually work? This is not yet fixed and can be discussed about. Does this have to integrate with the actual derivation recipe format or not? I think it is convenient (and more uniform) to have override semantics be the same for the recipe as for the final evaluated derivation.
- How should the
stdenvbe defined? What are all the cross-compiled dependencies required? What is the platform triple ofmkDerivation?? - How to avoid setup hooks breaking everything? Can this be offloaded to Nix? Aren't there better ways to write a general builder?
- Should the
stdenvbootstrapping happen through the add-append extension type? How to make this streamlined for different platforms? - Platforms are expanded into many attributes in Nixpkgs, which ones are interesting? Which ones are necessary?
- Similar to Nixpkgs, how does security patching work? Is "grafting" a possible option? Is there anything better than just waiting for upstream patches?
- Is evaluation time a concern? Identical package scopes are not deduplicated when used as different dependencies, is this a problem?
Credits #
Most of my inspiration comes from some excellent work in PR #227327 and PR #273815. Credits to the wonderful contributors adding ideas and suggestions to these discussions.
Finally also thanks to all the readers who will hopefully be motivated to give me feedback and work on a better nix experience for the future. Actively suggesting improvements is the best way to help this prototype grow into a practical and proven project. The craziest ideas are most welcome because these have sometimes the most chance of actively improving the UX of the ecosystem.